
Lo importante es el contexto
Los avances más significativos en la inteligencia artificial ya no se centran exclusivamente en el tamaño o la potencia del modelo de lenguaje grande (LLM) en sí. La nueva frontera, que define el paso de las demostraciones experimentales a los sistemas de producción robustos, reside en la calidad, relevancia y dinamismo de la información proporcionada al modelo. En este nexo surge la Ingeniería de Contexto, la disciplina formal dedicada al diseño, la gestión y la optimización de este ecosistema de información.
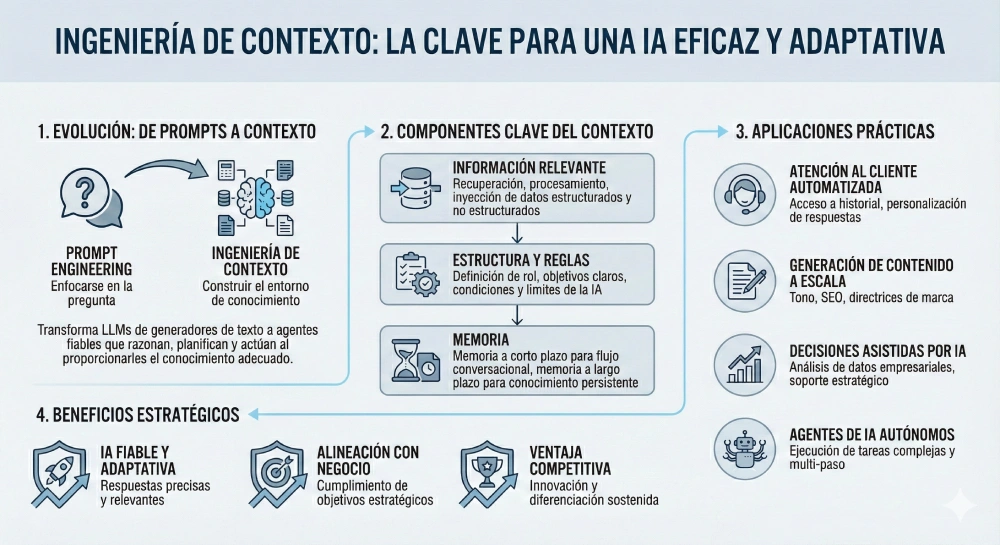
Este cambio de paradigma redefine fundamentalmente la interacción con la IA. Mientras que la Ingeniería de Prompts (Prompt Engineering) fue el arte de formular la pregunta correcta, la Ingeniería de Contexto es la ciencia de construir un entorno en el que la IA ya posea el conocimiento adecuado para responderla. Esta evolución es lo que transforma a los LLM de ser generadores de texto inteligentes a convertirse en agentes fiables y orientados a objetivos.
La promesa de esta disciplina es inmensa: la Ingeniería de Contexto es la clave para desbloquear agentes de IA verdaderamente adaptativos y autónomos. Estos agentes son capaces de gestionar tareas complejas de varios pasos, personalizadas según el usuario, ancladas en la realidad a través de datos externos y alineadas con los objetivos estratégicos de negocio. Es la arquitectura que permite a la IA no solo responder, sino razonar, planificar y actuar.
II. La Evolución Inevitable: Por Qué la Ingeniería de Prompts Fue Solo el Principio 📈
El Auge del "Artesano de Prompts" 🎨
Con la llegada de LLM de acceso público como ChatGPT a finales de 2022, surgió rápidamente una nueva habilidad práctica: la Ingeniería de Prompts. Se convirtió en el método principal para guiar el comportamiento de estos modelos sin necesidad de reentrenamientos costosos. Sus técnicas principales incluían la asignación de roles ("Actúa como un abogado experto..."), la provisión de ejemplos de alta calidad en el propio prompt ( few-shot learning) y la instrucción de seguir un razonamiento paso a paso (chain-of-thought) para problemas complejos. Este enfoque trataba la interacción con la IA como una habilidad del usuario, un arte para obtener mejores resultados a través de una redacción ingeniosa.
El Límite Transaccional: Identificando las Limitaciones 🧱
A pesar de su eficacia inicial, pronto se hizo evidente que los enfoques basados únicamente en prompts tenían un techo fundamental, especialmente para la construcción de aplicaciones sofisticadas y de nivel empresarial.
Falta de Estado (Statelessness): Los LLM son inherentemente apátridas; no tienen memoria de interacciones pasadas a menos que esa información se reinyecte manualmente en cada nuevo prompt. Esto hace que las conversaciones de múltiples turnos sean frágiles, ineficientes y difíciles de escalar.
Conocimiento Estático: Los prompts son cadenas de texto estáticas que no pueden adaptarse a datos en tiempo real ni a eventos ocurridos después de la fecha de corte del entrenamiento del modelo. Esto deja al LLM operando con una visión del mundo obsoleta.
Falta de Escalabilidad: Un enfoque centrado en el prompt no escala para flujos de trabajo empresariales complejos que requieren integración con múltiples fuentes de datos, API y reglas de negocio. Como señaló el investigador Sundeep Teki, este método proporciona al modelo una "visión del mundo incompleta y a medio cocinar".
De un Oficio a una Disciplina de Ingeniería 🏗️
El reconocimiento de estas limitaciones impulsó un cambio conceptual fundamental. La industria comenzó a pasar del "ajuste experimental a la ingeniería profesional". El foco ya no estaba en la habilidad del usuario para formular una pregunta, sino en la arquitectura del sistema que proporciona al modelo la información necesaria.
La Ingeniería de Prompts trata la interacción con la IA como un problema de usuario, centrándose en la interfaz humano-modelo. Por el contrario, la Ingeniería de Contexto la aborda como un problema de sistemas, centrándose en la arquitectura de información que soporta al modelo.
Este cambio no es meramente semántico; representa la maduración de todo el campo del desarrollo de IA. El proceso de interactuar con un LLM dejó de ser un oficio artesanal para convertirse en una disciplina de ingeniería estructurada. El desarrollo de sistemas y pipelines para gestionar el flujo de información hacia el LLM marcó un alejamiento del contenido del prompt para centrarse en el proceso de su creación. Prácticas como tratar el contexto como un "producto" sujeto a control de versiones, controles de calidad, monitorización y benchmarking son un reflejo directo de los principios establecidos en la ingeniería de software y DevOps. Por lo tanto, la Ingeniería de Contexto no es simplemente un "prompting avanzado"; es la aplicación de principios de ingeniería sistemáticos, repetibles y escalables al desafío de la comunicación con un LLM.
III. Deconstruyendo la Ingeniería de Contexto: La Arquitectura de los Sistemas Inteligentes 🏛️
Una Definición Formal 📖
La Ingeniería de Contexto puede definirse formalmente como la disciplina sistemática de diseñar, construir y gestionar dinámicamente el entorno de información completo (contexto) proporcionado a un modelo de IA durante la inferencia para garantizar que sus resultados sean precisos, relevantes, fiables y alineados con objetivos complejos. Gobierna lo que el modelo sabe, no solo lo que se le pregunta.
Los Pilares de una Arquitectura Centrada en el Contexto 🏛️
Un sistema robusto de ingeniería de contexto se basa en varios pilares fundamentales que trabajan en conjunto para crear un entorno de información coherente y eficaz.
Ensamblaje Dinámico de Contexto: El contexto no es una plantilla estática, sino que se construye sobre la marcha para cada tarea, evolucionando a medida que avanza la conversación. Este proceso implica ensamblar instrucciones del sistema, la entrada del usuario, documentos recuperados, resultados de herramientas y la memoria del sistema.
Sistemas de Memoria Integrales: Es crucial diferenciar entre la memoria a corto plazo (historial de chat, búferes de conversación) para mantener el contexto inmediato, y la memoria a largo plazo (almacenes de vectores, perfiles de usuario) para la personalización y la continuidad entre sesiones.
Integración de Fuentes de Conocimiento: La ingeniería de contexto conecta los LLM con el mundo exterior a través de bases de datos externas, API y flujos de datos en tiempo real. El patrón principal para lograr esto es la Generación Aumentada por Recuperación (RAG).
Gestión Estratégica de la Ventana de Contexto: Un desafío crítico es gestionar la ventana de contexto limitada del modelo. Esto requiere técnicas como la sumarización, la puntuación de relevancia y la compresión para asegurar que la información más vital esté presente sin causar distracción o confusión.
Seguridad y Consistencia: Para aplicaciones de nivel empresarial, son indispensables requisitos como la sanitización del contexto (eliminación de información personal identificable), la detección de inyección de prompts y el control de acceso basado en roles para garantizar operaciones de IA seguras y conformes a las normativas.
La siguiente tabla resume las diferencias fundamentales entre ambos enfoques, solidificando la comprensión del cambio de paradigma.
| Atributo 📝 | Ingeniería de Prompts (El Oficio 🎨) | Ingeniería de Contexto (El Sistema 🏗️) |
| Alcance | Estrecho: Se centra en una única cadena de entrada o instrucción. | Amplio: Gestiona todo el ecosistema de información alrededor del modelo. |
| Objetivo | Obtener la mejor respuesta posible para una tarea única e inmediata. | Construir sistemas de IA fiables, con estado y escalables para tareas complejas de varios pasos. |
| Enfoque | El arte de formular la pregunta. Una habilidad orientada al usuario. | La ciencia de diseñar el entorno de información. Un problema a nivel de sistema. |
| Escala Temporal | Transaccional y sin estado: "Para el momento", se reinicia con cada interacción. | Persistente y con estado: Gestiona el contexto a través de múltiples turnos, sesiones y usuarios. |
| Complejidad | Baja: A menudo una única entrada de texto autocontenida. | Alta: Implica la orquestación de múltiples componentes (RAG, memoria, herramientas, API). |
| Analogía | Dirigir una conversación. | Diseñar la sala donde tiene lugar la conversación. |
| Tecnología Representativa | Ejemplos few-shot, asignación de roles, prompts de cadena de pensamiento. | Pipelines de RAG, bases de datos vectoriales, módulos de memoria, frameworks de uso de herramientas (p. ej., LangChain). |
IV. El Conjunto de Herramientas del Ingeniero: Mecanismos Centrales de la Ingeniería de Contexto 🛠️
Esta sección profundiza en los mecanismos técnicos que sustentan la ingeniería de contexto, explicando el "cómo" detrás de la teoría.
1. Generación Aumentada por Recuperación (RAG): La Base de una IA Anclada en la Realidad ⚓
¿Qué es RAG? RAG es el patrón fundacional de la ingeniería de contexto. Su función es anclar los LLM en conocimiento externo y verificable, reduciendo drásticamente las alucinaciones y superando el problema del conocimiento obsoleto.
El Pipeline de RAG Básico: El proceso clásico, a menudo denominado RAG "ingenuo", consta de cuatro etapas clave, basadas en revisiones académicas exhaustivas.
Indexación: Implica la limpieza de datos, la segmentación en fragmentos (chunks), la creación de representaciones numéricas (embeddings) y su almacenamiento en una base de datos vectorial.
Recuperación: Dada una consulta del usuario, el sistema codifica la pregunta y busca en la base de datos los chunks más relevantes mediante una búsqueda de similitud semántica.
Aumentación: Los fragmentos recuperados se concatenan con el prompt original del usuario, un proceso a veces llamado prompt stuffing.
Generación: Finalmente, el LLM produce una respuesta basada en este prompt aumentado y rico en contexto.
Más Allá del RAG Básico: Arquitecturas Avanzadas y Modulares: Los sistemas de producción rara vez utilizan el RAG ingenuo. Para abordar los desafíos de precisión en la recuperación y relevancia del contexto, se emplean técnicas avanzadas. Estas incluyen optimizaciones previas a la recuperación (como la expansión o el enrutamiento de consultas), procesamiento posterior a la recuperación (como el reordenamiento o la compresión de los resultados) y diseños modulares que permiten una recuperación iterativa y adaptativa, donde el propio modelo puede decidir cuándo y qué buscar.
2. Construyendo la Memoria: De Conversaciones Efímeras a Conocimiento Persistente 🧠
La Necesidad de un Estado: Como se mencionó, los LLM son apátridas. Los sistemas de memoria resuelven este problema fundamental, permitiendo a un agente mantener una interacción coherente, personalizada y continua a lo largo del tiempo.
Memoria a Corto Plazo (Conversacional): Esta es la "memoria de trabajo" del agente. Generalmente se implementa como un búfer de conversación que almacena los turnos más recientes o un resumen continuo de la interacción. Su propósito es seguir el flujo inmediato del diálogo.
Memoria a Largo Plazo (Persistente): Esta es la base de conocimiento del agente sobre un usuario o tema específico, que persiste a través de múltiples sesiones. Es crucial para la personalización y el aprendizaje a lo largo del tiempo. A menudo se almacena en bases de datos vectoriales o perfiles estructurados. Un ejemplo claro es un agente de viajes que recuerda la preferencia de un usuario por las catas de vino de viajes anteriores para informar futuras recomendaciones.
3. Habilitando la Acción: Uso de Herramientas e Integración de API ⚡
De Respondedores a Actores: El uso de herramientas es el mecanismo que transforma a un LLM de un procesador de información pasivo a un agente activo capaz de realizar tareas en el mundo real.
Cómo Funciona: El proceso implica proporcionar al agente un conjunto de herramientas disponibles (generalmente API) junto con sus descripciones. Basándose en la solicitud del usuario y el contexto actual, el LLM decide qué herramienta invocar, con qué parámetros, y luego integra la salida de la herramienta de nuevo en su contexto para formular una respuesta final.
El Desafío de la Gestión de Herramientas: Un problema común es la "confusión de herramientas", donde proporcionar a un agente demasiadas herramientas o descripciones deficientes degrada su rendimiento. Investigaciones han demostrado que la solución es la gestión de la carga de herramientas mediante RAG: en lugar de presentar todas las herramientas a la vez, se utiliza un sistema de recuperación para seleccionar dinámicamente solo las más relevantes para la tarea en cuestión, mejorando drásticamente la precisión.
Estos tres mecanismos no son simplemente un conjunto de características, sino un sistema profundamente interconectado y jerárquico. RAG proporciona el conocimiento, la Memoria proporciona el estado, y el Uso de Herramientas proporciona la acción. Un agente no puede realizar una acción significativa (Uso de Herramientas) sin comprender la tarea actual y su historial (estado de la Memoria). Por ejemplo, un agente de correo electrónico necesita recordar el hilo de la conversación antes de decidir programar una reunión. A su vez, la capacidad de un agente para razonar y actuar está severamente limitada si no puede acceder a información externa y actualizada (conocimiento de RAG). Un agente financiero no puede dar buenos consejos (acción) sin datos de mercado en tiempo real (conocimiento). Incluso la propia memoria a largo plazo se construye a menudo sobre patrones de RAG, recuperando interacciones pasadas de un almacén vectorial. Por lo tanto, estos mecanismos forman una pila en capas donde el conocimiento fundamenta el estado y el estado informa la acción. La ingeniería de contexto es la disciplina de construir y gestionar esta pila.
V. El Resultado Final: Construyendo Agentes de IA Dinámicos y Adaptativos ✨
Sintetizando el Agente 🤖
Un contexto bien diseñado es el "sistema operativo" o el "andamiaje" que permite el comportamiento agéntico. Un agente no es solo el LLM; es todo el sistema que recopila contexto, planifica y ejecuta. La ingeniería de contexto es lo que permite a estos sistemas pasar de ser reactivos a proactivos.
El Bucle Agéntico 🔄
El flujo de trabajo fundamental de un agente sigue un ciclo de percepción, planificación, acción y observación.
Percibir: El agente ingiere la entrada del usuario y ensambla el contexto inicial utilizando RAG y la memoria.
Planificar: Descompone el objetivo de alto nivel en una secuencia de pasos ejecutables.
Actuar: Ejecuta un paso, que puede implicar llamar a una herramienta, consultar una base de datos o generar texto.
Observar: Integra el resultado de la acción de nuevo en el contexto, actualizando su estado.
Repetir: Continúa el bucle hasta que se alcanza el objetivo. Frameworks modernos como LangGraph están diseñados específicamente para gestionar este proceso cíclico y con estado, proporcionando control y flexibilidad.
Impacto en el Mundo Real: Casos de Uso de la Ingeniería de Contexto 🏢
La transición de la teoría a la práctica se hace evidente al examinar cómo las empresas están aprovechando estos principios para crear valor real.
Soporte al Cliente (DoorDash): DoorDash implementó un chatbot basado en RAG para su soporte a repartidores. El sistema utiliza un "LLM Guardrail" para verificar la conformidad de las respuestas con las políticas de la empresa y un "LLM Judge" para evaluar continuamente la calidad. Este enfoque de contexto controlado garantiza respuestas precisas y reduce los tiempos de resolución.
Servicios Financieros (Block): La empresa Block (anteriormente Square) utiliza el Protocolo de Contexto de Modelo (MCP) para conectar sus LLM a datos de pagos y comerciantes en tiempo real. Esto permite una resolución de problemas dinámica y automatizada, pasando de prompts estáticos a un entorno rico en información viva.
Desarrollo de Software (GitHub/Microsoft): Los asistentes de codificación avanzados utilizan el contexto de todo el código base, la arquitectura del proyecto y los cambios recientes para proporcionar sugerencias altamente relevantes. Esto ha demostrado aumentar la productividad de los desarrolladores y reducir significativamente los errores en el código generado, ya que el agente comprende el "porqué" detrás del código, no solo el "qué".
Marketing en Ciencias de la Vida (Caidera.ai): Caidera.ai se enfrenta al desafío de un marketing altamente regulado, donde cada afirmación debe ser verificada con fuentes científicas. Utilizan un sistema multiagente impulsado por LlamaIndex para automatizar este proceso. LlamaParse y LlamaCloud se utilizan para ingerir documentos científicos, permitiendo a los agentes crear contenido de marketing que ya está pre-verificado para el cumplimiento normativo. Los resultados son notables: una reducción del 70% en el tiempo de creación de campañas y procesos de cumplimiento 3 veces más rápidos.
Estos casos demuestran que la ingeniería de contexto no es una mejora opcional para las empresas, sino un requisito fundamental. La transición de demostraciones públicas a aplicaciones internas seguras, fiables y conformes es imposible sin una arquitectura de contexto robusta. Las empresas operan con datos propietarios, sensibles y en constante cambio. Un LLM estático y preentrenado es inherentemente inadecuado para este entorno. La ingeniería de contexto es la tecnología habilitadora que hace que los LLM estén listos para la empresa, abordando directamente los riesgos de negocio asociados con las alucinaciones y garantizando que la seguridad y la gobernanza estén integradas en la arquitectura del sistema, no dejadas al azar en un prompt.
VI. Navegando la Frontera: Desafíos, Mejores Prácticas y el Futuro 🧭
Obstáculos Prácticos en la Implementación 🚧
Construir estos sistemas es complejo y presenta desafíos únicos, a menudo denominados "fallos de contexto".
Envenenamiento del Contexto (Context Poisoning): Ocurre cuando una alucinación o un error temprano contamina la memoria del agente, lo que lleva a una cascada de fallos posteriores. La mitigación clave es la validación rigurosa del contexto antes de que se ingiera en la memoria a largo plazo.
Distracción del Contexto (Context Distraction): Conocido como el problema de "perdido en el medio", un contexto excesivamente largo puede hacer que el modelo ignore información crucial o comience a repetirse. Las estrategias de mitigación incluyen la sumarización del contexto y el reordenamiento (re-ranking) para priorizar la información más relevante.
Latencia y Costo: Cada recuperación de RAG, llamada a una API y turno del LLM añade latencia y costo computacional. La optimización de los pipelines, el uso de cachés y la utilización de modelos más pequeños y rápidos para tareas intermedias son cruciales para mantener la eficiencia.
Mejores Prácticas para Construir Sistemas Conscientes del Contexto ✅
Para los profesionales que construyen estas aplicaciones, varias prácticas recomendadas han surgido como esenciales.
Tratar el Contexto como un Producto: Aplicar la disciplina de la ingeniería de software al contexto: control de versiones, pruebas de calidad y monitorización continua para la mejora iterativa.
Comenzar con RAG: Utilizar RAG como el enfoque predeterminado para incorporar conocimiento externo. El ajuste fino (fine-tuning) debe reservarse para enseñar un estilo o comportamiento específico, no para inyectar hechos.
Iterar y Evaluar Implacablemente: La construcción de agentes es un proceso iterativo. Utilizar frameworks de evaluación como LangSmith o Vellum para probar diferentes estrategias de contexto y medir objetivamente los resultados es fundamental para el éxito.
Incorporar al Humano en el Bucle (Human-in-the-Loop): Para tareas críticas, diseñar agentes que busquen la aprobación humana antes de ejecutar acciones. Esto genera confianza y proporciona una capa de seguridad crucial.
El Futuro del Contexto y la IA Agéntica 🔮
La ingeniería de contexto está sentando las bases para el futuro de la inteligencia artificial, que se perfila en varias direcciones clave.
Nuevos Roles Profesionales: Están surgiendo roles especializados como "Arquitecto de Contexto", "Ingeniero de Orquestación de LLM" y "Diseñador de Productos de IA", que se centran en la arquitectura de la información en lugar de en la redacción de prompts.
Evolución Arquitectónica: Se observa un movimiento hacia arquitecturas basadas en eventos, que permiten una comunicación más flexible y escalable entre componentes. Además, los sistemas multiagente, donde equipos de agentes especializados colaboran y comparten contexto para resolver problemas aún más complejos, se están convirtiendo en una realidad.
Consideraciones Éticas: A medida que los sistemas de contexto gestionan datos cada vez más sensibles, la IA responsable se vuelve primordial. El enfoque debe centrarse en la transparencia, la equidad, la rendición de cuentas y la privacidad para garantizar un despliegue ético y seguro.
En conclusión, el futuro de la IA no es una única superinteligencia monolítica, sino un ecosistema colaborativo de agentes especializados, todos impulsados por un contexto meticulosamente diseñado. El objetivo es pasar de herramientas reactivas a colaboradores virtuales proactivos y orientados a objetivos que amplifiquen el potencial humano, automatizando procesos complejos y permitiendo una toma de decisiones más inteligente y adaptativa. La ingeniería de contexto no es solo el siguiente paso después de la ingeniería de prompts; es la base sobre la que se construirá esta nueva generación de inteligencia artificial